
Devenue incontournable à l’heure de la digitalisation de notre société, l’IA suscite autant d’espoir et d’admiration que d’inquiétudes. La raison : la performance des algorithmes est privilégiée au détriment de leur transparence et explicabilité. Cette situation crée une certaine méfiance voire défiance des consommateurs et des citoyens entraînant par la même une grande confusion dans la compréhension des enjeux au moment ou l’on parle d’IA de confiance.
Par Pascal MONTAGNON, Directeur de la Chaire de Recherche Digital, Data Science et Intelligence Artificielle – OMNES EDUCATION, et, Eric BRAUNE, Professeur associé – INSEEC Bachelor
Avec la généralisation de l’usage des systèmes de prise de décision automatique, qu’ils soient fondés sur des modèles logiques (systèmes experts…) ou des statistiques (machine learning, deep learning…), il est important de pouvoir expliquer, interpréter et confirmer les résultats obtenus par les algorithmes, d’autant qu’ils s’imposent inexorablement dans la vie quotidienne des individus : transactions bancaires, traque à la fraude fiscale et sociale, nouvelles méthodes de recrutement, traçabilité de la navigation sur les équipements digitaux, reconnaissance faciale, contrôle accru de la productivité des salariés, octroi de prêts bancaires, chatbots, ou encore la sélection des étudiants dans l’enseignement supérieur (l’algorithme utilisé pour Parcoursup a mis en avant le manque de transparence des algorithmes utilisés par les universités pour inscrire les étudiants), etc.
Jusqu’à une période récente, les algorithmes et les décisions qui en découlaient issus des formules et d’équations mathématiques, étaient fortement influencés par les développeurs, leur culture, leur façon de voir les choses. Désormais, ces règles relèvent davantage de propriétés “cachées” dans les données à partir desquelles les algorithmes vont apprendre d’eux-mêmes en fonction du volume et de la qualité de la data traitée. Ces algorithmes sont réputés difficiles à comprendre, tant pour leur développeur expert que pour l’utilisateur profane, parce que leurs procédures d’optimisation sont précisément en rupture avec les modalités de raisonnement humain, et ne peuvent être aisément reproduites à l’identique.
Même si ces algorithmes restent à l’origine, toujours plus ou moins sous l’influence du développeur, la décision qui en résultera pourra lui échapper en grande partie laissant ainsi entier tous les problèmes dus à la complexité, à l’opacité et parfois à la non-compréhension des solutions proposées par l’algorithme.
D’un point de vue mathématique, la recherche d’un bon modèle d’apprentissage automatique met l’accent sur la minimisation d’une fonction de coût ou la maximisation d’une fonction de vraisemblance. Ainsi, la performance du modèle est mesurée presque exclusivement sur les résultats par rapport à des métriques correctement choisies. Cette tendance a conduit à créer des algorithmes de plus en plus sophistiqués et complexes au détriment de leur explicabilité. Il est vrai, par ailleurs, que ce qui rend les algorithmes d’apprentissage automatique difficiles à comprendre, est aussi ce qui fait d’eux d’excellents prédicteurs.
Pour bien comprendre, il nous semble important à ce stade de présenter ci-après le schéma conceptuel de création d’une application favorisant l’Apprentissage Machine (AM), et notamment la sélection du type de données, son traitement, ainsi que le choix et la combinaison des variables dites explicatives qui sont la source de choix ontologiques pouvant être générateurs de manipulations.
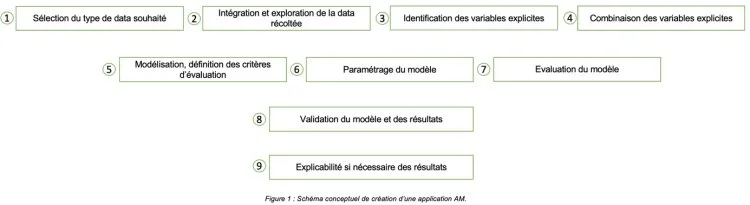
Le schéma ainsi décrit dissèque les différentes étapes de la conception d’une application procédant par AM. Comme dans tout système incluant de l’IA, la data constitue l’ingrédient de base devant servir le modèle souhaité de sa création à son exploitation finale jusqu’à éventuellement son explicabilité. Un point de vigilance est à mettre en évidence à cet instant : des contraintes ontologiques en termes de format et de traitement, engendrées elles-mêmes par des choix de conception, peuvent influencer le comportement et donc l’explicabilité de cette application.
Des systèmes experts aux arbres de décision en passant par les forêts aléatoires et les classifications, et plus généralement tous les modèles de Machine Learning basés sur des symboles et opérations sont interprétables sans grandes difficultés. Tous peuvent s’exprimer de manière analytique, avec à la clé des successions de variables, aux poids différents, ou encore répondant de règles logiques différentes.
C’est pourquoi les notions de transparence, interprétabilité et explicabilité suscitent autant de questionnements que d’inquiétudes.
Tout d’abord parlons de transparence.
La transparence des algorithmes fait occurrence dans des contextes variés, et reçoit des définitions explicites diverses qui méritent un effort de clarification.
La première difficulté rencontrée est la polysémie [1] du mot transparence renforcée par le développement de l’IA ces dernières années, sujet devenu très sensible. La transparence d’un algorithme peut faire référence à deux types de propriétés [2] : Extrinsèques, comme la loyauté et l’équité, ou Intrinsèques, comme l’interprétabilité et l’explicabilité.
Selon le type de propriété, la notion de transparence peut être variable. Mais un principe de base s’impose : un algorithme est, et doit être fondamentalement imaginé conçu comme une machine. Ne lui prêtons pas une capacité à avoir des réactions type racisme, discriminantes ou encore sexistes. Pour autant, il ne faut pas ignorer que l’usage des algorithmes peut bien sûr produire des effets de cet ordre en exécution de sa programmation, généralement au-delà des effets souhaités par son concepteur. Il est à noter que parfois, parmi la littérature existante sur le sujet, il arrive que l’on distingue une confusion entre les termes « algorithme » et « programme » qui sont utilisés à mauvais escient. Il existe une distinction intuitive entre ces deux termes. Un algorithme est une approche mathématique décrivant une procédure ; le programme quant à lui, est une approche technique, qui utilise un algorithme dans un langage de programmation donné. Bien qu’il ne soit pas aisé de faire la distinction entre ces deux approches compte tenu de la diversité des langages de programmation, on ne peut pas nier le rôle heuristique que cette distinction apporte à l’univers de l’AM et de l’IA en général.
Quel que soit la programmation utilisée et l’algorithme associé, le principe de fonctionnement reste basé sur l’exploitation de la donnée. Les données d’entrée sont connues mais leur exploitation réalisée tout au cours de l’AM amènera progressivement le développeur à se sentir dépossédé de la maîtrise du processus quant à la parfaite assimilation des données de sorties. Ainsi, la décision automatisée issue de l’exploitation de ces algorithmes s’est opacifiée. On parle alors de « boîte noire ». Ce phénomène est accentué par le corpus de données utilisés qui ne cesse de croître et renforce le recours à des solutions algorithmiques tant la quantité de data à intégrer est devenu volumineux rendant improbable la prise en compte par un cerveau humain. Il devient alors indispensable de comprendre les critères pris en compte derrière leurs propositions de décision issues d’algorithme d’IA. Le besoin de confiance et de transparence devient nécessaire et oblige une vraie réorientation des problématiques liées au Machine Learning notamment le besoin de les expliquer [3].
Interprétabilité ou explicabilité ?
Les besoins de transparence et de confiance dans les algorithmes de Machine Learning, comme les réseaux de neurones ou les mécanismes d’apprentissage par renforcement, ont ainsi fait émerger deux concepts qu’il ne faut pourtant pas confondre et qu’il convient d’éclaircir : l’interprétabilité et l’explicabilité.
L’interprétabilité consiste à comprendre le raisonnement de l’algorithme de Machine Learning et la représentation interne des données utilisées dans un format compréhensible par un individu. Le résultat obtenu est bien évidemment en relation avec la quantité, la qualité, la parfaite connaissance des données utilisées et aussi du modèle retenu [4]. Autrement dit l’interprétabilité répond à la question « comment » un algorithme prend-il une décision (quelles données prises en compte, quelles méthodes de calcul, etc).
L’explicabilité quant à elle consiste à fournir une information utilisant un langage accessible à tout utilisateur, quel qu’il soit et quelle que soit son niveau de connaissances ou d’expertise sur le sujet en question. [Gilpin et al., 2018]. Le vocabulaire utilisé est adapté selon les situations à la cible de ceux qui vont recevoir cette information. Autrement dit, l’explicabilité répond aux questions « De quoi parle-t-on ? », « A quoi cela sert-il ? », « Pourquoi et dans quel but le fait-on ? ».
Peut-on, ou doit-on, tout expliquer ou interpréter ? Est-ce même souhaitable ?
La réponse ne s’impose pas naturellement. Bien sûr il est nécessaire de démystifier ces “boîtes noires” et de renforcer la transparence pour justifier les résultats obtenus par le Machine Learning. Pour autant faut-il se limiter l’interprétabilité et d’explicabilité des algorithmes ? A l’évidence non. On parle désormais d’IA de confiance qui va bien au-delà de ces deux concepts.
Alors que jusqu’à présent, le développement de l’IA reposait sur des briques logicielles installées sur des serveurs informatiques centralisés (cloud), les prochaines étapes, déjà visibles de tous, consistent à embarquer directement l’IA au plus près de son usage, de l’objet connecté aux systèmes en passant par les installations industrielles.
Pour ce faire, cette IA embarquée doit répondre à de nombreux critères dont entre autres, la performance, la sobriété et la confiance. La performance et la sobriété sont tellement importantes pour embarquer l’IA dans l’exploitation de systèmes souvent critiques, permettant de réduire considérablement les besoins en communication et d’énergie associées tout en imposant des contraintes fortes sur la performance des composants électroniques. Cette IA de confiance embarquée localement (au plus près de l’utilisateur) se doit notamment de garantir la sûreté (absence de défaillances présentant des risques pour les individus, les biens ou l’activité économique), la sécurité (cybersécurité, protection de la data), la robustesse et la fiabilité des mécanismes de décision des applications d’IA.
Concrètement, la confiance se décline sur tous les éléments de construction des systèmes d’IA pour in fine justifier la confiance auprès de ses utilisateurs.
Pour conclure, vous l’aurez compris, les algorithmes d’intelligence artificielle ont des niveaux d’opacité différents. Selon le type d’algorithme, certains sont plus facilement explicables, d’autres restent ostensiblement opaques. Selon la qualification et la quantité des données utilisées, l’interprétabilité amenant l’explicabilité sera aisée ou extrêmement complexe malgré l’entraînement algorithmique.
Alors, Faut-il renforcer la transparence et l’explicabilité des algorithmes ? La transparence souhaitée sur un algorithme ne garantit pas que l’on puisse aboutir systématiquement à son explicabilité.
Pourtant, nous pensons qu’il est devenu nécessaire de rendre explicable toutes les bases qui ont servies à la construction d’un algorithme qui permettrait de comprendre de manière optimale, comment celui-ci fonctionne à la fois en termes de pertinence (mais qui en douterait ?), et d’éthique en évitant toute forme de discrimination. Cette méthode, appelée « fairness » en anglais, en est encore à ses balbutiements.
Enfin, n’oublions pas un principe de base : en IA comme en statistiques, il y aura toujours un biais de généralisation dont il conviendra de minimiser autant que possible les effets au maximum.
[1] Polysémie : adjectif désignant un mot qui a plusieurs sens.
[2] Maël Pégny, Issam Ibnouhsein. Quelle transparence pour les algorithmes d’apprentissage machine? . 2018. hal-01877760
[3] Kate Crawford and Trevor Paglen, 2019 – Excavating AI : The Politics of Images in Machine Learning Training Sets
[4] Gilpin and al, 2018 – Explaining Explanations: An Overview of Interpretability of Machine Learning – Cornell University
Article rédigé par :
Pascal MONTAGNON – Directeur de la Chaire de Recherche Digital, Data Science et Intelligence Artificielle – OMNES EDUCATION
Eric BRAUNE – Professeur associé – INSEEC Bachelor
<<< A lire également : Intelligence artificielle : Faut-il se méfier des algorithmes ? >>>



