
Les efforts de transformation numérique, accélérés par la pandémie, auront permis une rapide adoption des technologies cloud native, parmi lesquelles les microservices et Kubernetes.
Ces architectures applicatives de nouvelle génération présentent d’énormes avantages pour les entreprises, notamment en termes de rapidité d’innovation, de flexibilité et de fiabilité. Mais de nombreuses équipes informatiques sont aujourd’hui sous pression pour surveiller et gérer la disponibilité et les performances dans des architectures cloud native complexes. En particulier, elles éprouvent des difficultés à avoir une visibilité complète sur les applications et l’infrastructure sous-jacente des environnements Kubernetes sur clouds publics.
Sans aucun doute, rester à la pointe de la disponibilité et des performances est bien plus difficile dans un environnement cloud, par nature dynamique, où tout change constamment en temps réel. Mais comme les initiatives de transformation numérique continuent de s’intensifier, les responsables informatiques n’ont d’autre choix que s’adapter et chercher à obtenir la visibilité dont ils ont besoin dans ces nouveaux environnements.
Une question de perspective
Historiquement, les problématiques de disponibilité et de performances étaient basées sur une infrastructure à durée de vie longue (physique ou virtualisée). Il y a dix ans, les services informatiques exploitaient un nombre fixe de serveurs et un réseau stable. Ils avaient des indicateurs stables et les mêmes tableaux de bord pour chacune des couches de la pile technologique. L’avènement du cloud a ajouté un nouveau niveau de complexité. Les entreprises se sont retrouvées à augmenter et à réduire continuellement leur utilisation des services IT en fonction de leurs besoins en temps réel.
Bien que les solutions de monitoring se soient adaptées au cloud – en parallèle des environnements traditionnels sur site – pour la plupart, elles n’ont pas été conçues pour gérer efficacement les environnements dynamiques cloud native d’aujourd’hui.
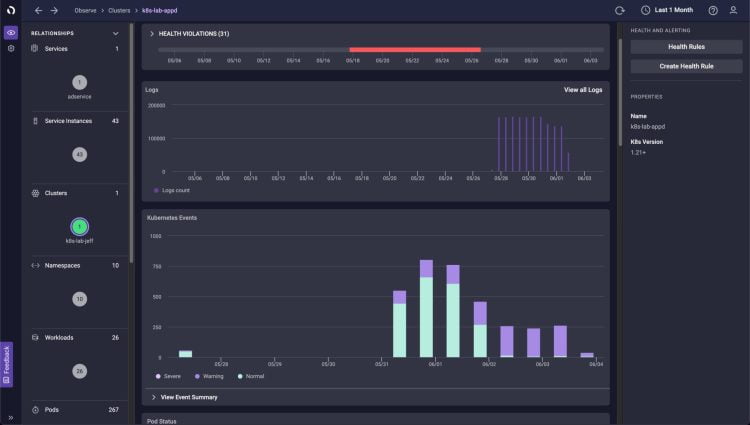
Ces systèmes distribués s’appuient sur des milliers de conteneurs et génèrent un volume important de métriques, événements, logs et traces (MELT) à chaque seconde. À l’heure actuelle, la plupart des responsables informatiques ne disposent tout simplement pas de la solution qui leur permettra de faire sens d’un tel volume de données. Ni de résoudre les problèmes de disponibilité et de performance de leurs applications, causés par des problèmes liés à une infrastructure dynamique et des interactions entre micro-services à vie courte.
L’observabilité cloud native, une solution indispensable
Pour que les responsables informatiques soient en mesure de comprendre correctement le comportement de leur parc applicatif, ils ont besoin de visibilité au niveau de l’application, des services numériques sous- jacents (tels Kubernetes) et de l’infrastructure cloud (calcul, serveur, base de données et réseau) qu’ils exploitent. Il est donc désormais essentiel pour eux de mettre en place une solution d’observabilité cloud native. Mais avant de se précipiter pour déployer une solution face à ce problème qui leur est posé, ils doivent tenir compte de facteurs importants.
Les responsables informatiques doivent chercher à déployer une solution conçue spécialement pour observer des applications cloud native, distribuées et dynamiques. Les solutions de monitoring traditionnelles continuent de jouer un rôle essentiel – et le feront encore pendant de nombreuses années – mais cela devient problématique lorsque la fonctionnalité du cloud est rajoutée sur des solutions de monitoring et d’APM existantes. Trop souvent, alors quede nouveaux cas d’usage sont ajoutés aux solutions existantes, les données restent cloisonnées, empêchant une visibilité complète. Les utilisateurs se voient contraints de passer d’une vue à l’autre pour tenter d’identifier les causes des problèmes de disponibilité et de performance. Beaucoup de solutions traditionnelles sont naturellement orientées vers une couche particulière de la pile technologique, qu’il s’agisse de l’application ou de l’infrastructure centrale.
De nouvelles équipes et de nouvelles approches
Les applications cloud native sont conçues différemment et sont gérées par de nouvelles équipes – Site Reliability Engineers (SRE), DevOps et CloudOps – avec de nouvelles compétences, mentalités et méthodes de travail. Elles attendent donc une nouvelle génération de technologies pour suivre et analyser les données de disponibilité et de performance de leurs environnements Cloud, notamment pour déchiffrer les interactions éphémères entre microservices – interactions qui peuvent avoir disparu depuis longtemps, une fois la résolution en cours.
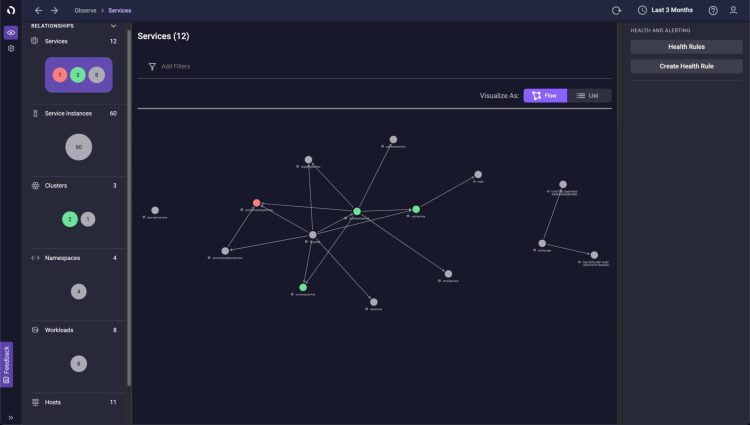
Les équipes SRE et DevOps ont aussi besoin d’une solution qui adopte des standards ouverts, offrant une vue complète et corrélée de toutes les données de télémétries de la pile technologique, notamment l’OpenTelemetry. Les responsables informatiques doivent être en mesure de collecter toutes ces données et de les analyser en même temps, puisqu’elles sont interconnectées et interdépendantes. Une solution fondée sur des normes est essentielle pour péréniser les investissements et préparer l’avenir des entreprises pour les dix prochaines années et au-delà.
Les responsables informatiques ont également besoin d’une solution qui leur permette de surveiller l’état des transactions métiers. Si un problème est détecté, ils doivent pouvoir assembler et analyser les données de télémétries de la transaction et ainsi déterminer rapidement la cause des problèmes, isoler le domaine de défaillance et diriger le problème vers les équipes compétentes pour une résolution rapide.
Enfin, les responsables informatiques devraient rechercher une solution qui combine l’observabilité avec des fonctionnalités IAOps avancées. Ils doivent tirer parti de la puissance de l’IAOps et de la visibilité métier pour prioriser les actions dans leur environnement cloud. À l’avenir, les entreprises utiliseront l’IA pour assister les équipes à détecter et à diagnostiquer les problèmes pour une résolution plus rapide. Finalement, cela permet aux responsables informatiques de se concentrer plus rapidement sur ce qui compte réellement, en fonction de l’impact métier, où et pourquoi cela s’est produit.
Le monde des applications a grandement évolué au cours des dernières années et les responsables informatiques doivent s’assurer que leurs capacités de surveillance suivent le rythme. Qu’il s’agisse de comprendre le fonctionnement des applications cloud native et de prévenir les incidents, ou d’adopter de nouvelles méthodes pour recueillir et analyser de grandes quantités de données de télémétries, les équipes DevOps, CloudOps et SRE ont besoin d’informations contextuelles de l’ensemble de la pile technologique.
Ce n’est donc qu’avec la bonne solution d’observabilité cloud native que les entreprises pourront maximiser les avantages des applications modernes, proposer des expériences numériques uniques à leurs utilisateurs et améliorer leurs résultats.

Par Erwan Paccard, Director Product Marketing, Cisco AppDynamics



